
Claude Opus 4.8 offers modest benchmark gains but delivers limited real‑world value compared to its predecessor. I've followed AI model releases long enough to recognize the pattern: announcements drop with fanfare, benchmarks look impressive on a slide, early testers (often partners or power users) sing praises, and then the real‑world feedback trickles in—mixed at best, quietly disappointed at worst. Anthropic's Claude Opus 4.8, released on May 28, 2026, fits this mold a little too neatly.
On paper, it's another step forward: sharper judgment, better "honesty" about its own limitations, stronger performance on agentic coding and long‑running tasks, and some genuinely useful new controls like adjustable effort levels. Anthropic even kept the pricing the same as Opus 4.7—$5 per million input tokens and $25 per million output for standard mode, doubling for the faster variant.
But dig a little deeper, talk to developers grinding away in messy codebases or knowledge workers dealing with edge cases, and a different picture emerges. This doesn't feel like the frontier‑pushing leap we were subtly promised. It feels like a polished iteration chasing diminishing returns while the company already teases its next, unreleased "Mythos" class model behind safety curtains.
Let me walk you through what we actually got, what people are saying, and why I'm left more pessimistic than excited.
What does Anthropic claim about Opus 4.8, and do the numbers back it up?
The official blog post is careful with its language. They describe Opus 4.8 as building on 4.7 with "improvements across benchmarks" and call it "a more effective collaborator." They admit it's a "modest but tangible improvement." That honesty is refreshing in an industry prone to breathless superlatives, but it also sets a low bar.
Key highlighted gains include:
- Coding and agents: 69.2% on SWE‑Bench Pro (up from 4.7), with claimed leadership over competing models. Strong showings on CursorBench across effort levels, Super‑Agent benchmark (only model to complete every case end‑to‑end), and computer‑use tests (84% on Online‑Mind2Web).
- "Honesty" and reliability: Roughly 4x less likely to miss flaws in its own code. More proactive about flagging uncertainties instead of confidently barreling ahead. This matters enormously for long‑running autonomous work.
- Legal and knowledge work: Harvey, an Anthropic partner, reported strong results on their internal Legal Agent Benchmark; Anthropic cites improvements in synthesis of long documents and self‑checking outputs. (Harvey has not published the full methodology or scores publicly as of this writing, so treat partner‑reported numbers with the usual skepticism.)
- New features: Effort control slider on claude.ai (low/medium/high/extra/max thinking depth—higher uses more tokens but delivers better results). "Dynamic workflows" in Claude Code for spinning up parallel sub‑agents, planning, verifying, and tackling massive codebase changes. API improvements like mid‑conversation system messages. 1M context window remains.
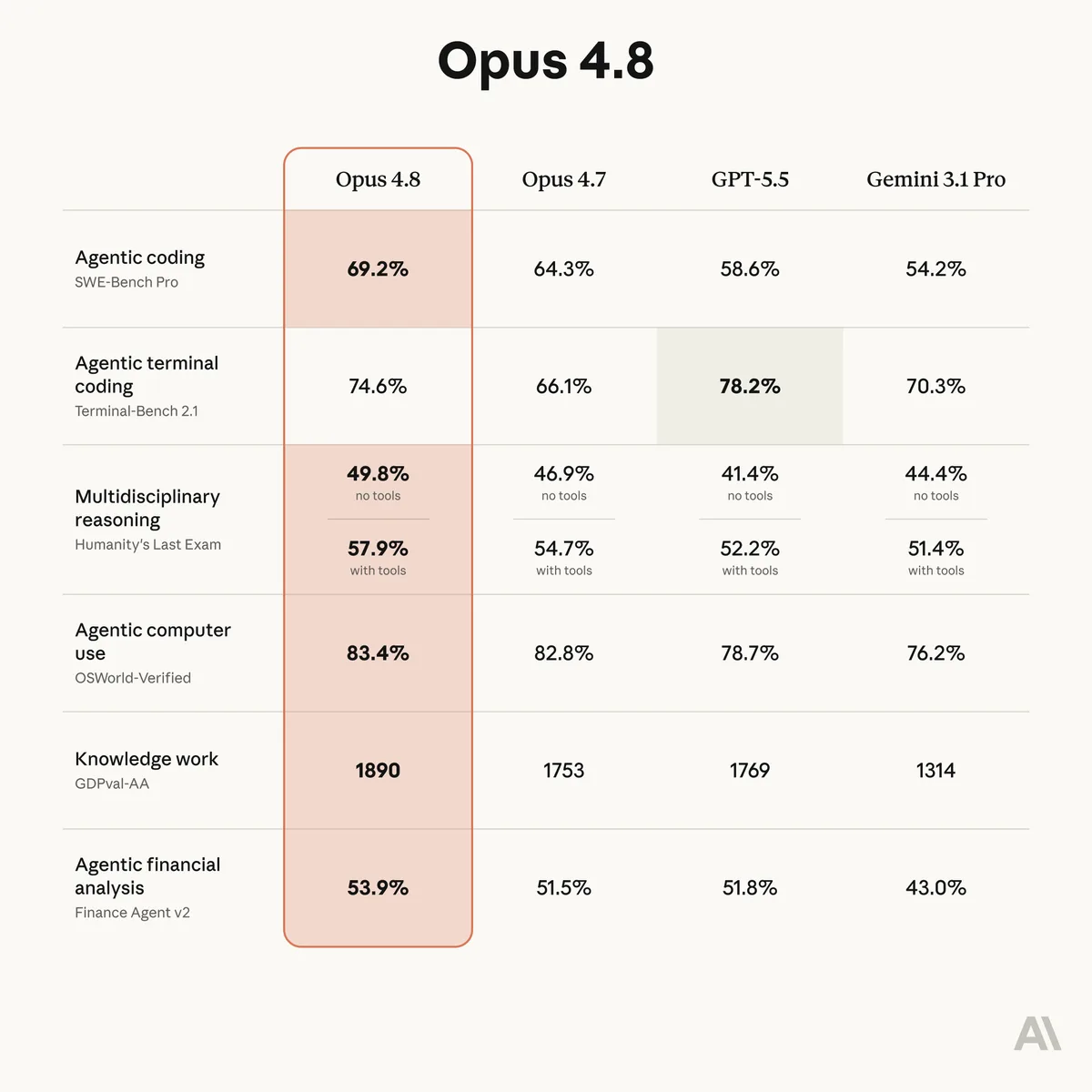
(Anthropic's launch image highlighting the model's new capabilities. Source: Official X post.)
These are real improvements on specific tests. Independent reviews back some of it. Dan Shipper's team at Every.to found Opus 4.8 topping their Senior Engineer benchmark (63/100 at extra‑high effort) and scoring 79.6 on writing—noticeably ahead of predecessors and competitors, with fewer "AI tells." They called it the most complete model they've tested and a "major quality‑of‑life update" for context‑carrying and collaboration.
Yet even positive coverage carries caveats. Output quality is heavily effort‑dependent. At lower settings it can slip into generic patterns; at max it gets expensive fast. The Claude app itself—split across Chat, Code, and Cowork tabs—still feels messy and slow compared to the model's potential. One reviewer noted they love the model but other leading models remain their daily driver for many tasks.
What are real‑world users saying about Opus 4.8 on X and Reddit?
This is where the pessimism deepens. Search "Opus 4.8" on X or Reddit and you'll see the split immediately. Power users and Anthropic's ecosystem partners (Cursor, Harvey, Databricks, Hebbia) offer glowing quotes about judgment, consistency, and reduced verbosity or tool‑calling issues from 4.7. One partner said it has "noticeably better judgment" and asks the right questions before making changes.
You might also like



But everyday testers tell a different story. One developer posted shortly after launch: "Hmmm I think maybe something is wrong with Opus 4.8. Claude has never hallucinated this badly for the past two weeks of my usage. This morning it kept making mistakes and tried to correct itself several times continuously."
Others called it incremental at best. "Yeah agreed - opus 4.8 was… incremental," one user replied in a thread. There are complaints about weird behaviors, like overly adversarial assumptions or odd internal references in its reasoning. Some Swedish‑language users noted regressions in basic comprehension that older models handled.
Lenny's Newsletter / YouTube testing captured the nuance well: Opus 4.8 shines on greenfield prototypes, one‑shot features, and fast execution. It struggles with "the last 10%," edge cases in existing codebases, and persistent hallucinations in trickier scenarios. That matches what many builders have whispered about recent Claude releases—great until it isn't, and you're left babysitting anyway.
Top AI voices have been relatively quiet in the first 24 hours, or at least my searches didn't surface scorching hot takes from the usual suspects like Andrej Karpathy or Yann LeCun. Elon Musk reportedly reposted the announcement with a positive "well done" nod. Ethan Mollick (per community mentions) used it productively for a full paper and even an RPG game. But the broader sentiment on X leans pragmatic rather than revolutionary: people are noting the honesty improvements as the real story, not raw intelligence. One thoughtful post put it perfectly: "I don't need another model that gives a brilliant answer in 20 seconds. I need one I can trust with an ugly repo… and ask: 'work through this properly.
check your own assumptions. don't perform progress.'" Whether 4.8 truly delivers that at scale remains to be seen.
Recall the trauma from Opus 4.7. Many users found it slower, more mechanical, prone to overthinking, and in some cases a regression from the beloved 4.6 in writing vibe and context handling. Complaints of it being "insanely bad" for certain creative or nuanced tasks weren't rare. Anthropic's quick follow‑up to 4.8 feels like damage control as much as planned iteration. When your flagship model lineup starts feeling like monthly software patches, you have to wonder about the underlying progress curve.
What do cost, diminishing returns, and the Mythos tease reveal about where we actually are?
Here's the rub for a pessimistic observer like me. These models are expensive to run at high effort on complex tasks. Token usage climbs fast, especially with 1M context or parallel sub‑agents. If the real‑world gains are marginal for many workflows—better on benchmarks, still flaky on your specific messy legacy codebase—then the value proposition frays.
We're also seeing clear signs of benchmark gaming and test‑specific optimization. Anthropic updates evaluation methodologies (they even revised prior Opus 4.7 scores in footnotes). That's normal, but it makes cross‑release and cross‑company comparisons slippery. Independent, reproducible evals in the wild will tell the longer story.
Meanwhile, Anthropic openly discusses working on a new "Mythos" class that outperforms Opus 4.8 on essentially everything but isn't ready for general release due to cybersecurity and safety concerns. Project Glasswing and stronger safeguards are in progress. So we get 4.8 as the public‑facing incremental model while the real leap stays in the lab. It's smart business, but it breeds fatigue. How many .x releases can users chase before the whole versioning scheme starts to feel like marketing theater?
The industry‑wide pattern worries me too. Rapid minor versions, each touted with new agentic superpowers, yet autonomous agents that truly "work unattended" without heavy human oversight remain elusive for most practical deployments. Opus 4.8 is better at saying "I'm not sure" or "this might be flawed"—which is progress on alignment and trustworthiness. But in practice, does that just mean more cautious refusals or extra prompting burden?
How useful is Opus 4.8 in practice, and does it actually live up to the hype?
Don't get me wrong — Opus 4.8 is probably worth trying if you're already deep in the Anthropic ecosystem, especially for coding‑heavy or structured knowledge work at high effort levels. The effort slider and dynamic workflows are thoughtful additions that could genuinely change workflows for some teams. The improved self‑awareness on task progress is a step in the right direction for agents.
But from where I sit, this release underscores a broader stagnation. We're squeezing incremental gains from ever‑larger models while real breakthroughs in reliability, cost‑efficiency, and true autonomy feel further away than the marketing suggests. The mixed reviews—one camp praising benchmark dominance and writing quality, the other reporting fresh hallucinations, edge‑case failures, and "incremental at best"— aren't a bug. They're the feature of where we are in the scaling curve.
If you're a builder or heavy user, test it yourself on your hardest tasks before committing. Temper the FOMO. The next "real" thing is always just around the corner — whether it's GPT‑5 or whatever OpenAI releases next, Gemini 3.something, or Anthropic's own Mythos. In the meantime, Opus 4.8 feels less like a revolution and more like another patch in an endless beta.
The hype machine will keep turning. I'll keep watching with a skeptical eye. You should too.
Frequently Asked Questions about Claude Opus 4.8
<script type="application/ld+json"> { "@context": "https://schema.org", "@type": "FAQPage", "mainEntity": [ { "@type": "Question", "name": "What are the main improvements in Claude Opus 4.8 over 4.7?", "acceptedAnswer": { "@type": "Answer", "text": "According to Anthropic's announcement, Opus 4.8 improves on coding and agentic tasks—hitting 69.2% on SWE-Bench Pro—and is roughly 4x less likely to miss flaws in its own code compared to 4.7. It also adds an effort control slider, dynamic parallel sub-agent workflows in Claude Code, and mid-conversation system message support via the API. Pricing held flat from 4.7." } }, { "@type": "Question", "name": "How much does Claude Opus 4.8 cost?", "acceptedAnswer": { "@type": "Answer", "text": "Anthropic kept pricing the same as Opus 4.
7: $5 per million input tokens and $25 per million output tokens for standard mode, with those rates doubling for the faster variant." } }, { "@type": "Question", "name": "What is the effort control slider in Claude Opus 4.8, and does it actually help?", "acceptedAnswer": { "@type": "Answer", "text": "The effort slider on claude.ai offers five levels—low, medium, high, extra, and max thinking depth. Higher settings consume more tokens but reportedly deliver better results. Independent testing by Dan Shipper's team at Every.to found their top scores came specifically at extra-high effort. The catch: max effort on complex tasks gets expensive fast, which cuts into the value proposition for many workflows."
} }, { "@type": "Question", "name": "Are real-world users getting the same results as the Claude Opus 4.8 benchmarks suggest?", "acceptedAnswer": { "@type": "Answer", "text": "Not consistently. Partner companies like Cursor and Harvey report strong gains in judgment and reliability. But a notable share of everyday developers on X and Reddit flagged hallucinations, called the release incremental at best, and noted regressions in some language tasks. Independent reviewers like Every.to were more positive but still flagged heavy effort-dependence and an imperfect native app experience." } }, { "@type": "Question", "name": "What is Anthropic's Mythos model, and why isn't it available yet?", "acceptedAnswer": { "@type": "Answer", "text": "Anthropic has openly discussed a new Mythos class model that reportedly outperforms Opus 4.
8 across the board. It isn't ready for general release because of cybersecurity and safety concerns Anthropic is still working through—they mention Project Glasswing and stronger safeguards as part of that effort. Opus 4.8 is the current public flagship while the more capable model stays in the lab." } } ] } </script>
Links for further reading:
Official announcement: https://www.anthropic.com/news/claude-opus-4-8
System card (detailed evals): https://www.anthropic.com/claude-opus-4-8-system-card
Every.to vibe check: https://every.to/vibe-check/opus-4-8-vibecheck
Lenny's testing coverage (via newsletter/YouTube summaries).



0 Comments
Log in to comment
Not a member yet? Join the community
Pick a meme
KlipyHave a great take?
Drop your email — we'll send a magic link so you can post it. No password.
Not a member of the community? Join today.
Join the community →